- -> Propose suite of tasks to evaluate preconditioned inference of commonsense knowledge in SOTA models
- [In preparation for NAACL2022] Qasemi E, Ilievski F, Chen M, Szekely P. PaCo: Preconditions Attributed to Commonsense Knowledge.
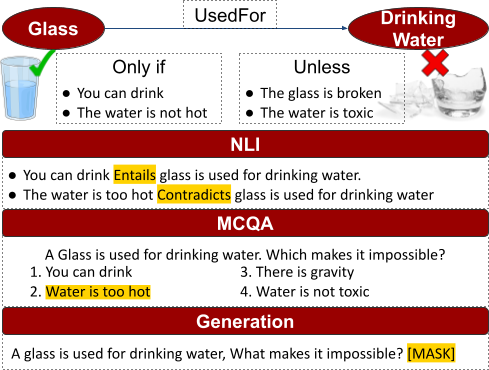
Humans can seamlessly reason with circumstantial preconditions of commonsense knowledge. We understand that a glass is used for drinking water, unless the glass is broken or the water is toxic. Despite state-of-the-art (SOTA) language models’ (LMs) impressive performance on inferring commonsense knowledge, it is unclear whether they understand the circumstantial preconditions. To address this gap, we propose a novel challenge of reasoning with circumstantial preconditions. We collect a dataset, called PaCo, consisting of 12.4 thousand preconditions of commonsense statements expressed in natural language. Based on this dataset, we create three canonical evaluation tasks and use them to examine the capability of existing LMs to understand situational preconditions. Our results reveal a 10-30% gap between machine and human performance on our tasks, which shows that reasoning with preconditions is an open challenge. Upon acceptance, we will release the dataset and the code used to test models.