- -> Depth estimation in urban scenes using Generative-Adversarial Networks (GAN)
- -> Full Presentation here
Depth estimation or Depth extraction refers to the set of methods and algorithms specifically aimed to obtain an
estimation of the spatial structure of a scene based on the Images or videos of it. In other terms, the goal is to
obtain a measure of the distance of, ideally, each point on these images1
. this notion on predicted depth, is an
essential component in the field of multi-view stereo2 or understanding the 3D geometry of the scene, which is
crucial in many applications3
, e.g. unmanned vehicle, robotics, and human body pose estimation4
.
Historically, researchers have looked at depth estimation problem in supervised learning setup. Models in this
setup attempt to directly predict the depth of each pixel in an image using models that have been trained off-line on
large collections of labeled datasets(ground truth depth data). Although these methods seem simple, there is no
universally acceptable method to generate this type of dataset, for two reasons. First, equipments necessary for
measuring depth data (e.g. laser sensors) are expensive and considered to be extremely noisy which introduced
additional challenge for current machine learning techniques. Second, even a in perfect world with noise-free
affordable equipments, discarding available bank of unlabeled Images and generating large datasets of labeled
data will restrict our model to scenes where labeled data is available. Consequently we need to generate sufficiently
representative and large datasets that requires large time and money investments.
In order to train a model while utilizing the currently available unlabeled (no depth dimension) image datasets,
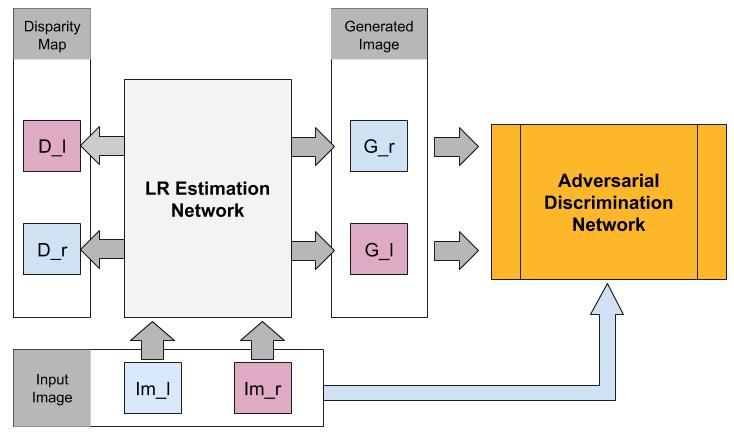
inspired by humans visual system, researchers have proposed monocular depth estimation methods that exploit
cues such as perspective, lighting, etc. One state-of-art method in this field is based on binocular image generation
using convolutional neural networks4
. In this project, we first aim at recreating the reported results in4
. Additionally
inspired by works in the field of adversarial learning5
, to learn consistency features used in training instead of
hard coding them, we plan to build on the adversarial idea to improve performance and training time of the depth
estimation model.