Ehsan Qasemi
CoreQuisite: Contextual Preconditions of Commonsense Knowledge.
Highlights:
- -> Evaluate reasoning with preconditions in SOTA models by proposing a multiple-choice question answering dataset
Publications:
- Qasemi E, Ilievski F, Chen M, Szekely P. CoreQuisite: Contextual Preconditions of Commonsense Knowledge. WeCNLP 2021
Details:
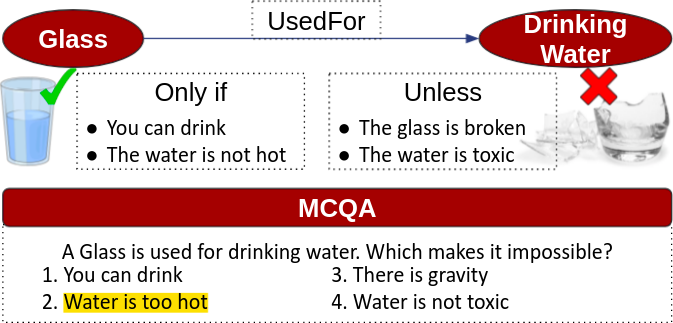
Humans can seamlessly reason with preconditions of commonsense knowledge such as a glass is used for drinking water, unless the glass is broken. Despite language models’ (LMs) impressive performance on inferring commonsense knowledge, it is unclear whether they as capable. We collect a dataset, called CoreQuisite, consisting of 12.4 thousand preconditions of commonsense statements expressed in natural language. Based on this dataset, we create a multiple-choice question answering (P-MCQA) evaluation task and use it to examine the capability of existing LMs to understand situational preconditions. Our results reveal a 30% gap between machine and human performance on our task, which shows the task is an open challenge.
Album: