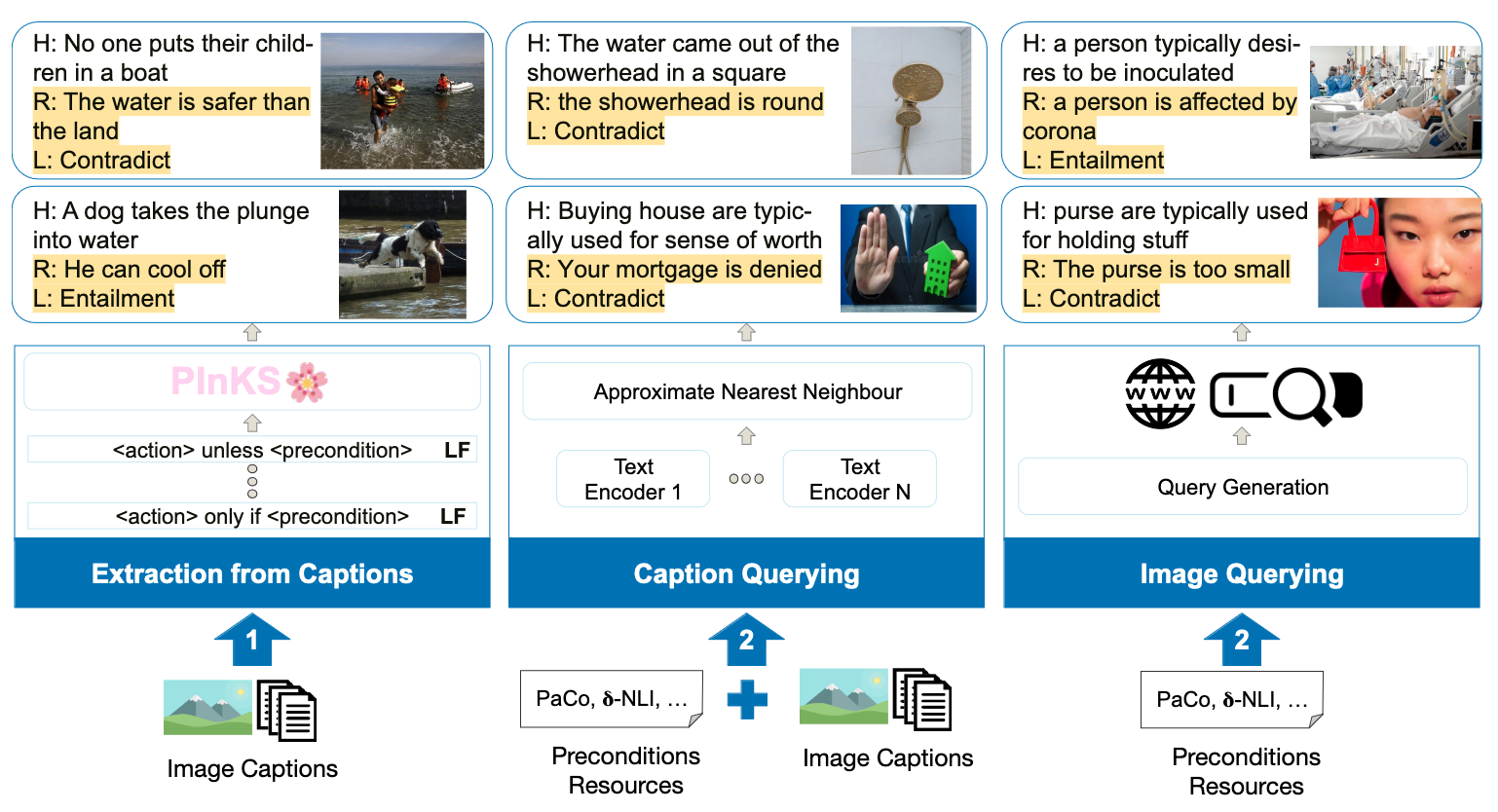
- -> Introduce a learning resource the task of preconditioned visual language inference and rationalization (PVLIR).
- [Under Review] Qasemi, Ehsan, Amani R. Maina-Kilaas, Devadutta Dash, Khalid Alsaggaf, and Muhao Chen. "Preconditioned Visual Language Inference with Weak Supervision." arXiv preprint arXiv:2306.01753 (2023).
Humans can infer the affordance of objects by extracting related contextual preconditions for each scenario. For example, upon seeing an image of a broken cup, we can infer that this precondition prevents the cup from being used for drinking. Reasoning with preconditions of commonsense is studied in NLP where the model explicitly gets the contextual precondition. However, it is unclear if SOTA visual language models (VLMs) can extract such preconditions and infer the affordance of objects with them. In this work, we introduce the task of preconditioned visual language inference and rationalization (PVLIR). We propose a learning resource based on three strategies to retrieve weak supervision signals for the task and develop a human-verified test set for evaluation. Our results reveal the shortcomings of SOTA VLM models in the task and draw a road map to address the challenges ahead in improving them.