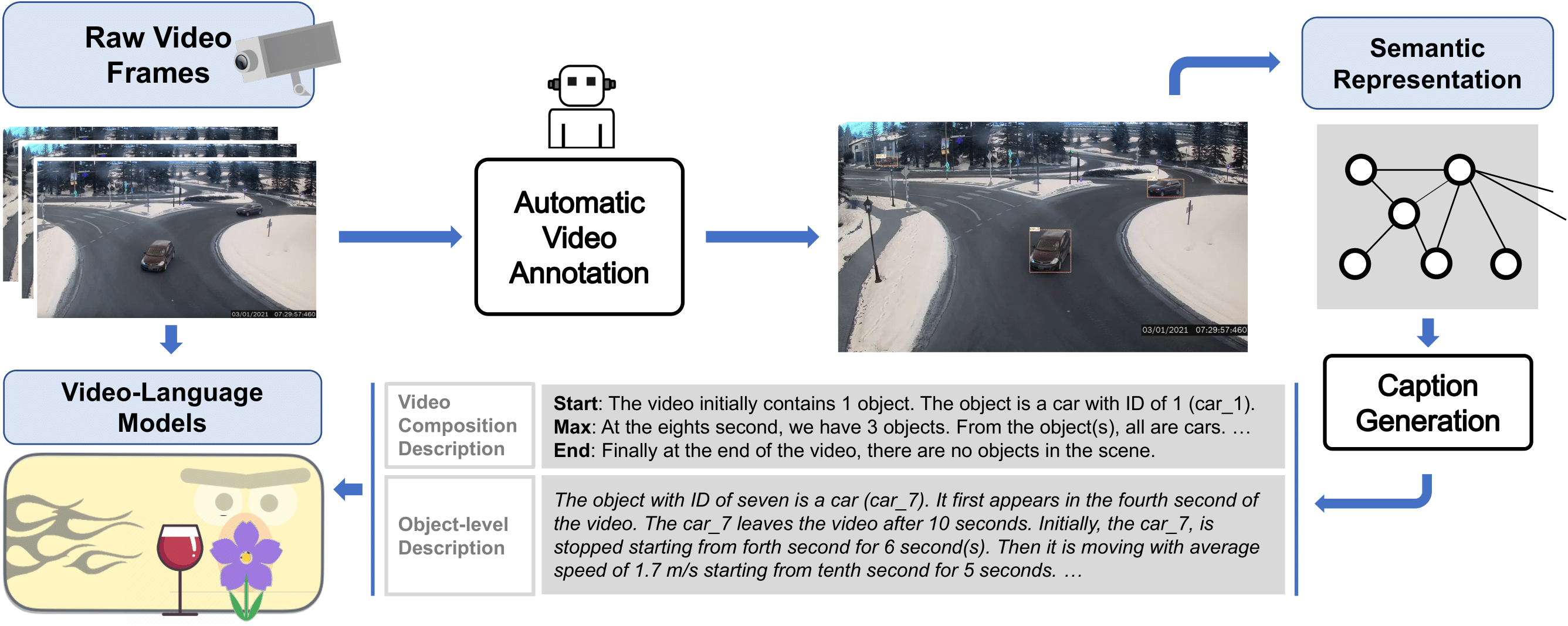
- -> Proposed a novel synthetic captioning method to incorporate traffic domain knowledge into video-language models, to improve Traffic question/answering performance of selective video-language models by 20%
- "Traffic-Domain Video Question Answering with Automatic Captioning", Qasemi E, Francis J. M., Oltramari A., ITSC 2023
Video Question Answering (VidQA) exhibits remarkable potential in facilitating advanced machine reasoning capabilities within the domains of Intelligent Traffic Monitoring and Intelligent Transportation Systems. Nevertheless, the integration of urban traffic scene knowledge into VidQA systems has received limited attention in previous research endeavors. In this work, we present a novel approach termed Traffic-domain Video Question Answering with Automatic Captioning (TRIVIA), which serves as a weak-supervision technique for infusing traffic-domain knowledge into large video-language models. Empirical findings obtained from the SUTD-TrafficQA task highlight the substantial enhancements achieved by TRIVIA, elevating the accuracy of representative video-language models by a remarkable 6.5 points (19.88%) compared to baseline settings. This pioneering methodology holds great promise for driving advancements in the field, inspiring researchers and practitioners alike to unlock the full potential of emerging video-language models in traffic-related applications.