- -> Build an automatic pipeline to calibrate and probe visible aspects of commonsense in visual language models.
- Singh, Shikhar, Ehsan Qasemi, and Muhao Chen. "VIPHY: Probing" Visible" Physical Commonsense Knowledge." arXiv preprint arXiv:2209.07000 (2022).
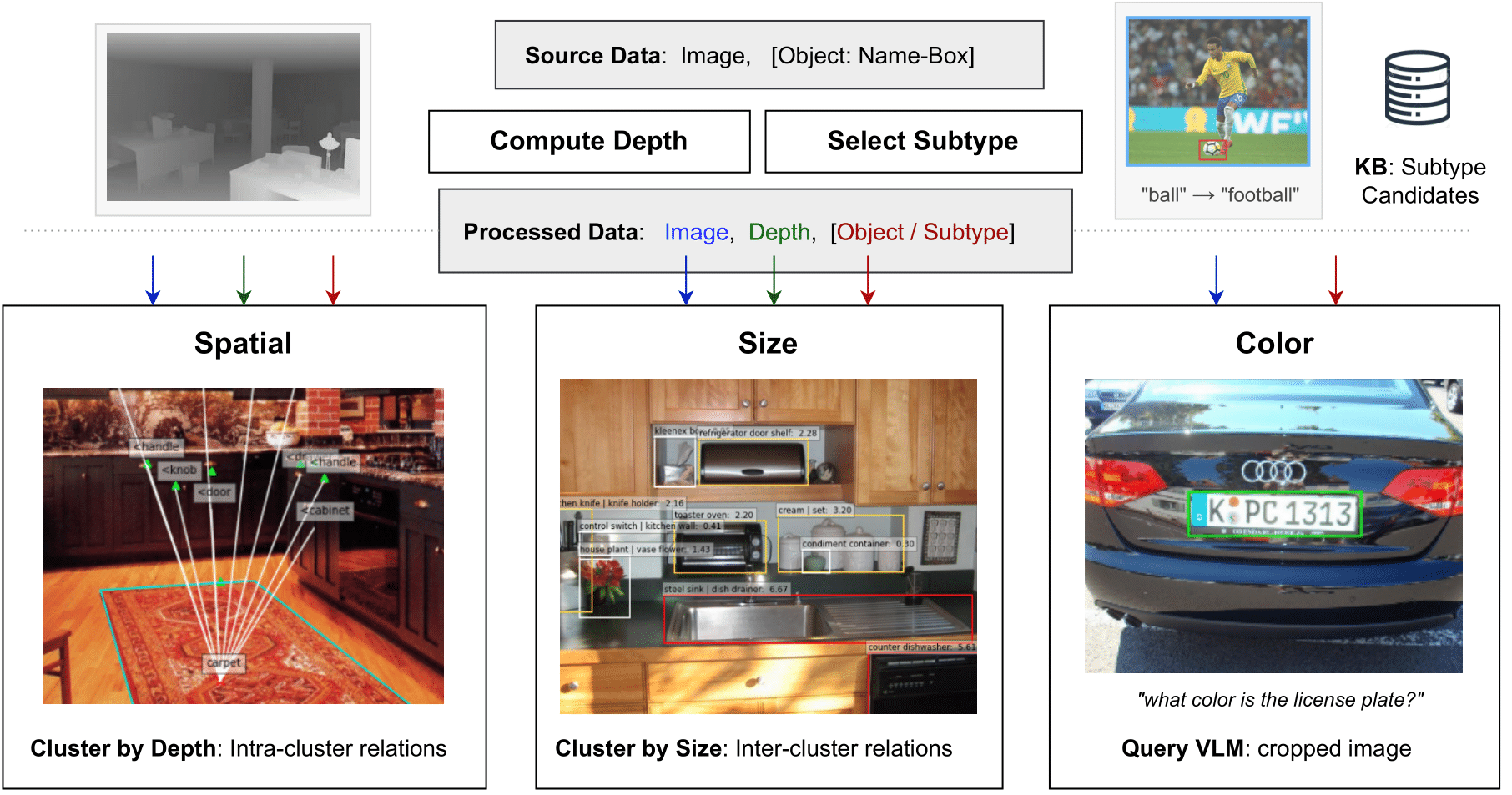
Vision-language models (VLMs) have shown remarkable performance on visual reasoning tasks (e.g. attributes, location). While such tasks measure the requisite knowledge to ground and reason over a given visual instance, they do not, however, measure the ability of VLMs to retain and generalize such knowledge. In this work, we evaluate VLMs’ ability to acquire “visible” physical knowledge – the informationthat is easily accessible from images of static scenes, particularly along the dimensions of object color, size, and space. We build an automatic pipeline to derive a comprehensive knowledge resource for calibrating and probing these models. Our results indicate a severe gap between model and human performance across all three dimensions. Furthermore, we demonstratethat a caption pretrained LM significantlyoutperforms VLMs on both size and spatialtasks – highlighting that despite sufficient accessto ground language with visual modality, they struggle to retain such knowledge.